Publications
* denotes equal first authorship.
2024
- ICML Oral
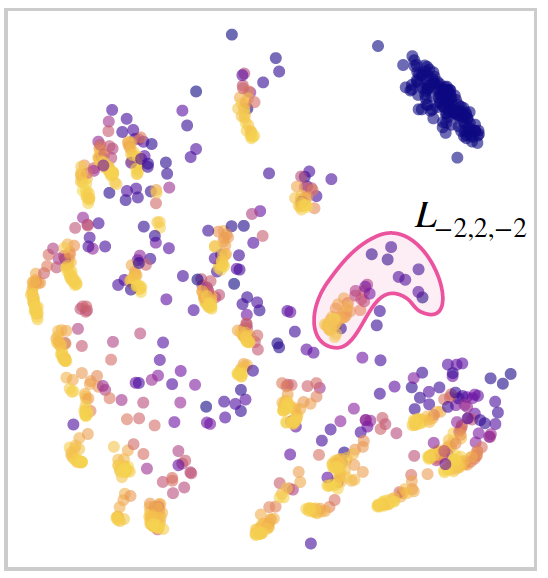 Learning Useful Representations of Recurrent Neural Network Weight MatricesVincent Herrmann, Francesco Faccio, and Jürgen SchmidhuberIn Forty-first International Conference on Machine Learning, 2024
Learning Useful Representations of Recurrent Neural Network Weight MatricesVincent Herrmann, Francesco Faccio, and Jürgen SchmidhuberIn Forty-first International Conference on Machine Learning, 2024Recurrent Neural Networks (RNNs) are general-purpose parallel-sequential computers. The program of an RNN is its weight matrix. How to learn useful representations of RNN weights that facilitate RNN analysis as well as downstream tasks? While the mechanistic approach directly looks at some RNN’s weights to predict its behavior, the functionalist approach analyzes its overall functionality – specifically, its input-output mapping. We consider several mechanistic approaches for RNN weights and adapt the permutation equivariant Deep Weight Space layer for RNNs. Our two novel functionalist approaches extract information from RNN weights by ’interrogating’ the RNN through probing inputs. We develop a theoretical framework that demonstrates conditions under which the functionalist approach can generate rich representations that help determine RNN behavior. We create and release the first two ’model zoo’ datasets for RNN weight representation learning. One consists of generative models of a class of formal languages, and the other one of classifiers of sequentially processed MNIST digits. With the help of an emulation-based self-supervised learning technique we compare and evaluate the different RNN weight encoding techniques on multiple downstream applications. On the most challenging one, namely predicting which exact task the RNN was trained on, functionalist approaches show clear superiority.
@inproceedings{herrmannlearning, title = {Learning Useful Representations of Recurrent Neural Network Weight Matrices}, author = {Herrmann, Vincent and Faccio, Francesco and Schmidhuber, J{\"u}rgen}, booktitle = {Forty-first International Conference on Machine Learning}, year = {2024}, } - ICML Oral
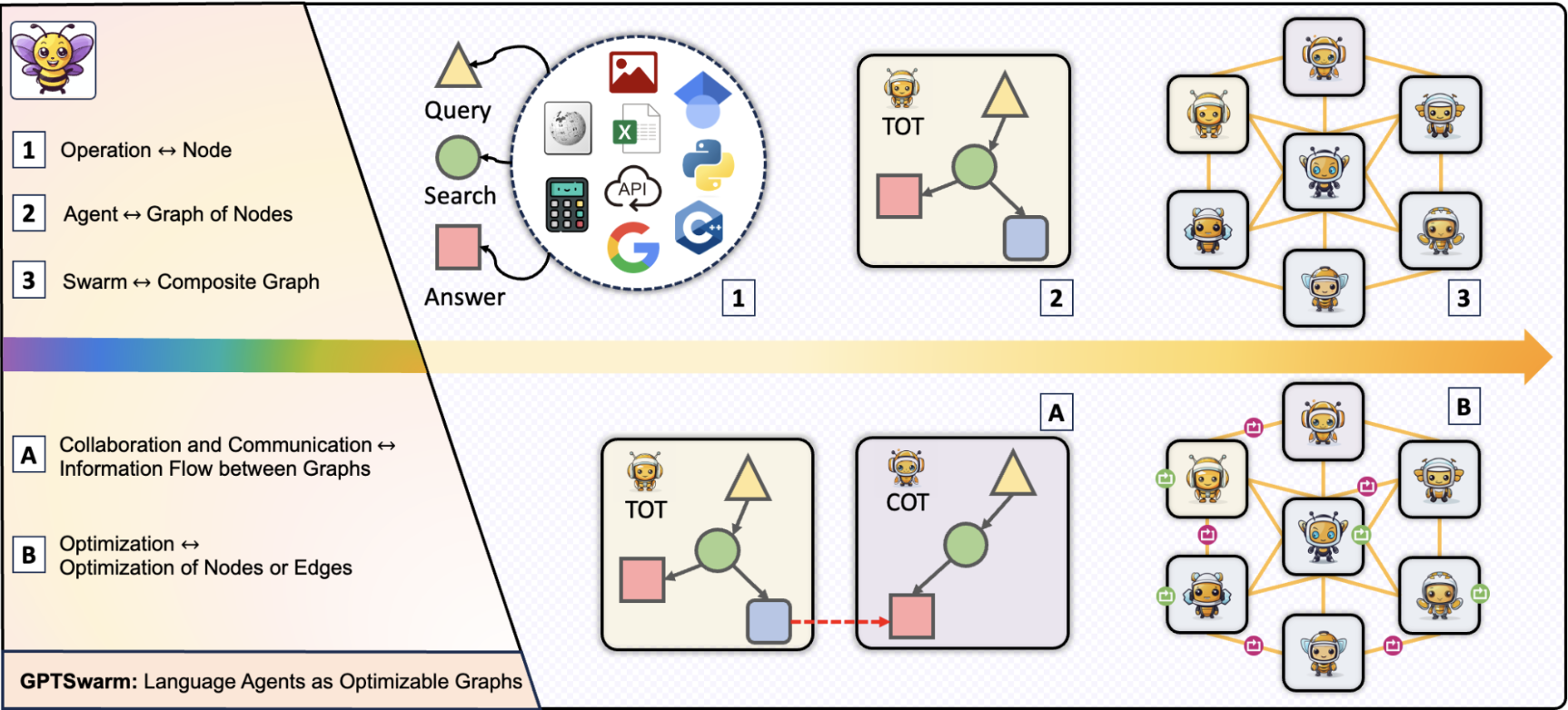 Language agents as optimizable graphsMingchen Zhuge, Wenyi Wang, Louis Kirsch, Francesco Faccio, Dmitrii Khizbullin, and 1 more authorIn Forty-first International Conference on Machine Learning, 2024
Language agents as optimizable graphsMingchen Zhuge, Wenyi Wang, Louis Kirsch, Francesco Faccio, Dmitrii Khizbullin, and 1 more authorIn Forty-first International Conference on Machine Learning, 2024Various human-designed prompt engineering techniques have been proposed to improve problem solvers based on Large Language Models (LLMs), yielding many disparate code bases. We unify these approaches by describing LLM-based agents as computational graphs. The nodes implement functions to process multimodal data or query LLMs, and the edges describe the information flow between operations. Graphs can be recursively combined into larger composite graphs representing hierarchies of inter-agent collaboration (where edges connect operations of different agents). Our novel automatic graph optimizers (1) refine node-level LLM prompts (node optimization) and (2) improve agent orchestration by changing graph connectivity (edge optimization). Experiments demonstrate that our framework can be used to efficiently develop, integrate, and automatically improve various LLM agents.
@inproceedings{zhuge2024language, title = {Language agents as optimizable graphs}, author = {Zhuge, Mingchen and Wang, Wenyi and Kirsch, Louis and Faccio, Francesco and Khizbullin, Dmitrii and Schmidhuber, J{\"u}rgen}, booktitle = {Forty-first International Conference on Machine Learning}, year = {2024}, } - Preprint
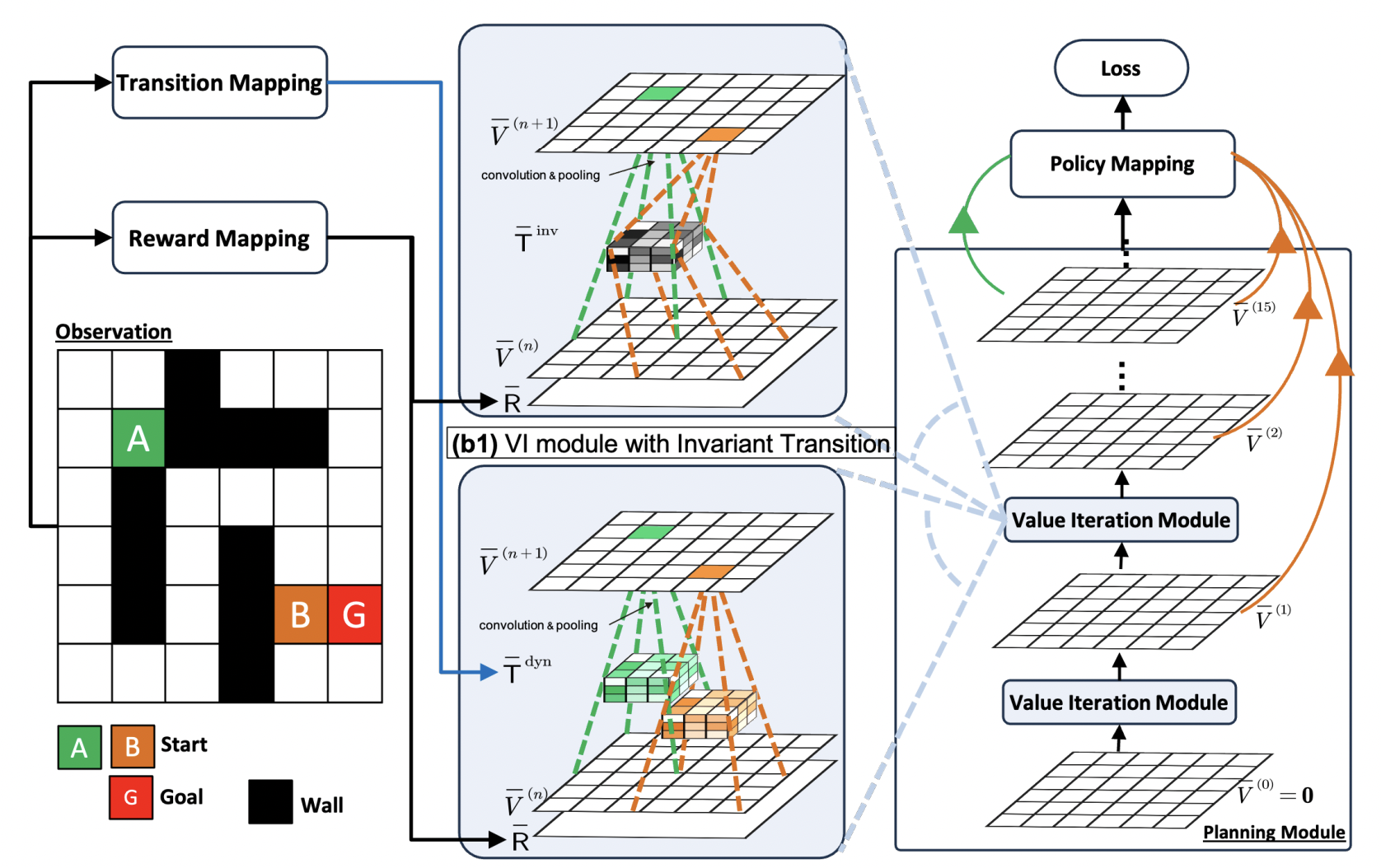 Scaling Value Iteration Networks to 5000 Layers for Extreme Long-Term PlanningYuhui Wang, Qingyuan Wu, Weida Li, Dylan R Ashley, Francesco Faccio, and 2 more authorsarXiv preprint arXiv:2406.08404, 2024
Scaling Value Iteration Networks to 5000 Layers for Extreme Long-Term PlanningYuhui Wang, Qingyuan Wu, Weida Li, Dylan R Ashley, Francesco Faccio, and 2 more authorsarXiv preprint arXiv:2406.08404, 2024The Value Iteration Network (VIN) is an end-to-end differentiable architecture that performs value iteration on a latent MDP for planning in reinforcement learning (RL). However, VINs struggle to scale to long-term and large-scale planning tasks, such as navigating a 100 x 100 maze – a task which typically requires thousands of planning steps to solve. We observe that this deficiency is due to two issues: the representation capacity of the latent MDP and the planning module’s depth. We address these by augmenting the latent MDP with a dynamic transition kernel, dramatically improving its representational capacity, and, to mitigate the vanishing gradient problem, introducing an "adaptive highway loss" that constructs skip connections to improve gradient flow. We evaluate our method on both 2D maze navigation environments and the ViZDoom 3D navigation benchmark. We find that our new method, named Dynamic Transition VIN (DT-VIN), easily scales to 5000 layers and casually solves challenging versions of the above tasks. Altogether, we believe that DT-VIN represents a concrete step forward in performing long-term large-scale planning in RL environments.
@article{wang2024scaling, title = {Scaling Value Iteration Networks to 5000 Layers for Extreme Long-Term Planning}, author = {Wang, Yuhui and Wu, Qingyuan and Li, Weida and Ashley, Dylan R and Faccio, Francesco and Huang, Chao and Schmidhuber, J{\"u}rgen}, journal = {arXiv preprint arXiv:2406.08404}, year = {2024}, } - Preprint
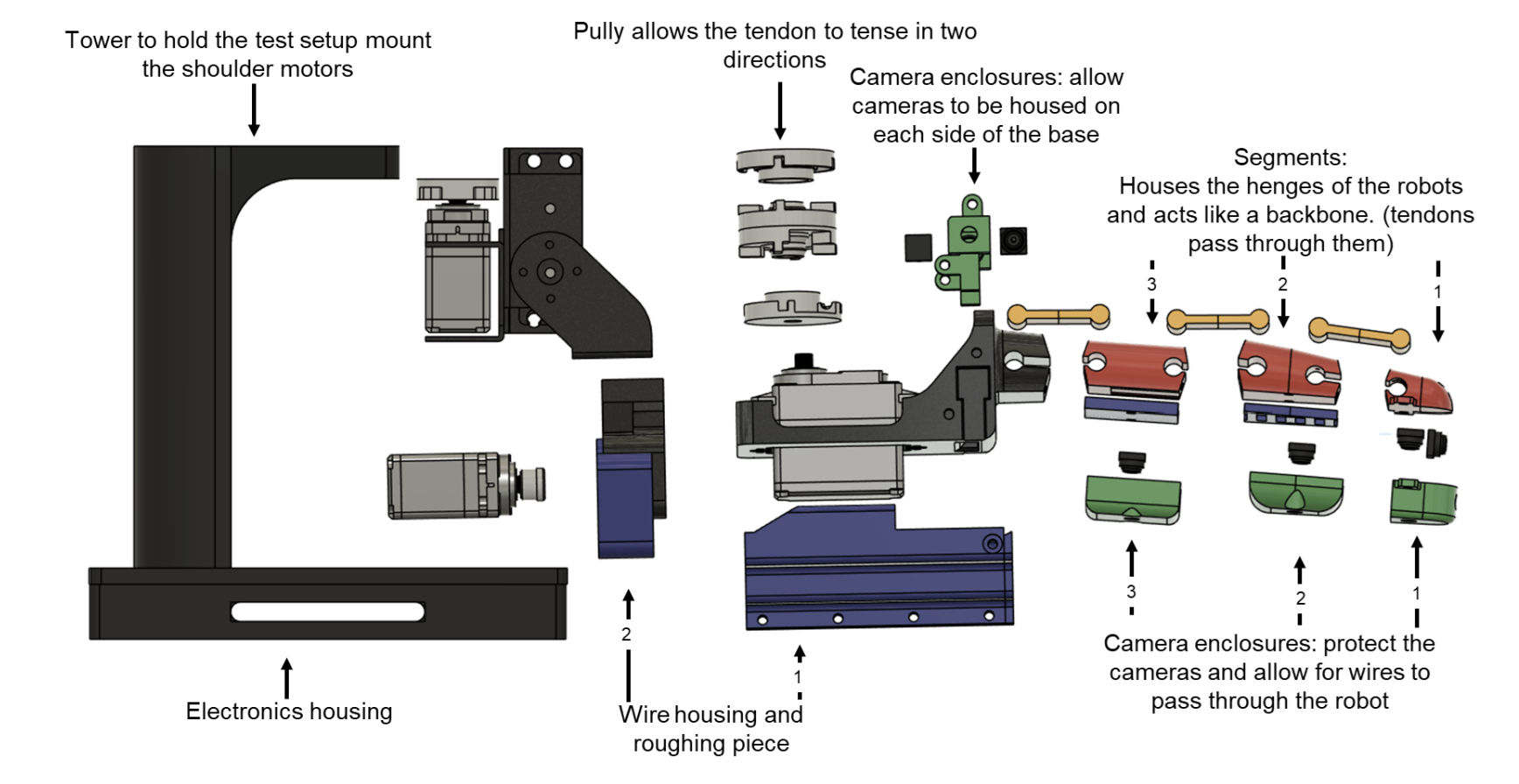 Towards a Robust Soft Baby Robot With Rich Interaction Ability for Advanced Machine Learning AlgorithmsMohannad Alhakami, Dylan R Ashley, Joel Dunham, Francesco Faccio, Eric Feron, and 1 more authorarXiv preprint arXiv:2404.08093, 2024
Towards a Robust Soft Baby Robot With Rich Interaction Ability for Advanced Machine Learning AlgorithmsMohannad Alhakami, Dylan R Ashley, Joel Dunham, Francesco Faccio, Eric Feron, and 1 more authorarXiv preprint arXiv:2404.08093, 2024Artificial intelligence has made great strides in many areas lately, yet it has had comparatively little success in general-use robotics. We believe one of the reasons for this is the disconnect between traditional robotic design and the properties needed for open-ended, creativity-based AI systems. To that end, we, taking selective inspiration from nature, build a robust, partially soft robotic limb with a large action space, rich sensory data stream from multiple cameras, and the ability to connect with others to enhance the action space and data stream. As a proof of concept, we train two contemporary machine learning algorithms to perform a simple target-finding task. Altogether, we believe that this design serves as a first step to building a robot tailor-made for achieving artificial general intelligence.
@article{alhakami2024towards, title = {Towards a Robust Soft Baby Robot With Rich Interaction Ability for Advanced Machine Learning Algorithms}, author = {Alhakami, Mohannad and Ashley, Dylan R and Dunham, Joel and Faccio, Francesco and Feron, Eric and Schmidhuber, J{\"u}rgen}, journal = {arXiv preprint arXiv:2404.08093}, year = {2024}, } - Preprint
 Faster Diffusion via Temporal Attention DecompositionHaozhe Liu, Wentian Zhang, Jinheng Xie, Francesco Faccio, Mengmeng Xu, and 4 more authorsarXiv preprint arXiv:2404.02747, 2024
Faster Diffusion via Temporal Attention DecompositionHaozhe Liu, Wentian Zhang, Jinheng Xie, Francesco Faccio, Mengmeng Xu, and 4 more authorsarXiv preprint arXiv:2404.02747, 2024We explore the role of attention mechanism during inference in text-conditional diffusion models. Empirical observations suggest that cross-attention outputs converge to a fixed point after several inference steps. The convergence time naturally divides the entire inference process into two phases: an initial phase for planning text-oriented visual semantics, which are then translated into images in a subsequent fidelity-improving phase. Cross-attention is essential in the initial phase but almost irrelevant thereafter. However, self-attention initially plays a minor role but becomes crucial in the second phase. These findings yield a simple and training-free method known as temporally gating the attention (TGATE), which efficiently generates images by caching and reusing attention outputs at scheduled time steps. Experimental results show when widely applied to various existing text-conditional diffusion models, TGATE accelerates these models by 10%-50%.
@article{liu2024faster, title = {Faster Diffusion via Temporal Attention Decomposition}, author = {Liu, Haozhe and Zhang, Wentian and Xie, Jinheng and Faccio, Francesco and Xu, Mengmeng and Xiang, Tao and Shou, Mike Zheng and Perez-Rua, Juan-Manuel and Schmidhuber, J{\"u}rgen}, journal = {arXiv preprint arXiv:2404.02747}, year = {2024}, } - ICML
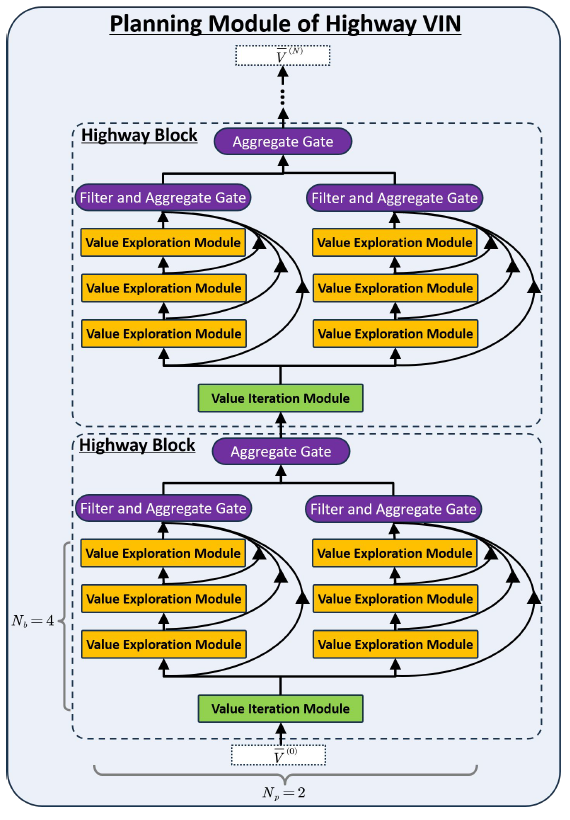 Highway Value Iteration NetworksYuhui Wang, Weida Li, Francesco Faccio, Qingyuan Wu, and Jürgen SchmidhuberIn Forty-first International Conference on Machine Learning, 2024
Highway Value Iteration NetworksYuhui Wang, Weida Li, Francesco Faccio, Qingyuan Wu, and Jürgen SchmidhuberIn Forty-first International Conference on Machine Learning, 2024Value iteration networks (VINs) enable end-to-end learning for planning tasks by employing a differentiable "planning module" that approximates the value iteration algorithm. However, long-term planning remains a challenge because training very deep VINs is difficult. To address this problem, we embed highway value iteration – a recent algorithm designed to facilitate long-term credit assignment – into the structure of VINs. This improvement augments the "planning module" of the VIN with three additional components: 1) an "aggregate gate," which constructs skip connections to improve information flow across many layers; 2) an "exploration module," crafted to increase the diversity of information and gradient flow in spatial dimensions; 3) a "filter gate" designed to ensure safe exploration. The resulting novel highway VIN can be trained effectively with hundreds of layers using standard backpropagation. In long-term planning tasks requiring hundreds of planning steps, deep highway VINs outperform both traditional VINs and several advanced, very deep NNs.
@inproceedings{wanghighway, title = {Highway Value Iteration Networks}, author = {Wang, Yuhui and Li, Weida and Faccio, Francesco and Wu, Qingyuan and Schmidhuber, J{\"u}rgen}, booktitle = {Forty-first International Conference on Machine Learning}, year = {2024}, } - Preprint
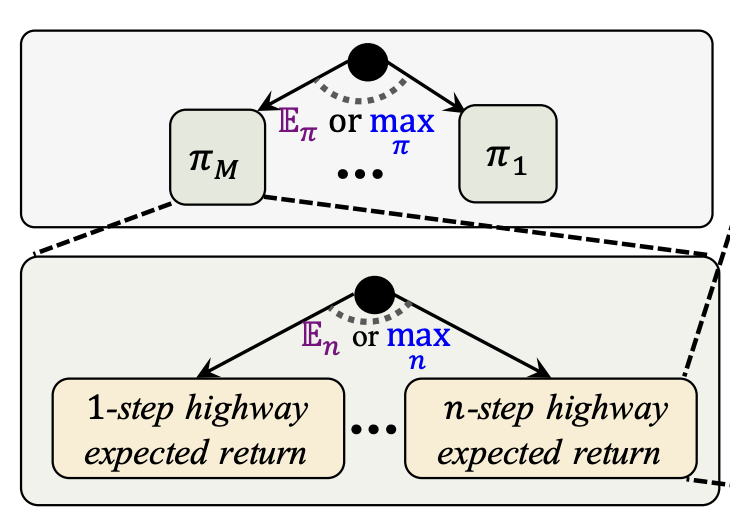 Highway reinforcement learningYuhui Wang, Miroslav Strupl, Francesco Faccio, Qingyuan Wu, Haozhe Liu, and 3 more authorsarXiv preprint arXiv:2405.18289, 2024
Highway reinforcement learningYuhui Wang, Miroslav Strupl, Francesco Faccio, Qingyuan Wu, Haozhe Liu, and 3 more authorsarXiv preprint arXiv:2405.18289, 2024Learning from multi-step off-policy data collected by a set of policies is a core problem of reinforcement learning (RL). Approaches based on importance sampling (IS) often suffer from large variances due to products of IS ratios. Typical IS-free methods, such as n-step Q-learning, look ahead for n time steps along the trajectory of actions (where n is called the lookahead depth) and utilize off-policy data directly without any additional adjustment. They work well for proper choices of n. We show, however, that such IS-free methods underestimate the optimal value function (VF), especially for large n, restricting their capacity to efficiently utilize information from distant future time steps. To overcome this problem, we introduce a novel, IS-free, multi-step off-policy method that avoids the underestimation issue and converges to the optimal VF. At its core lies a simple but non-trivial highway gate, which controls the information flow from the distant future by comparing it to a threshold. The highway gate guarantees convergence to the optimal VF for arbitrary n and arbitrary behavioral policies. It gives rise to a novel family of off-policy RL algorithms that safely learn even when n is very large, facilitating rapid credit assignment from the far future to the past. On tasks with greatly delayed rewards, including video games where the reward is given only at the end of the game, our new methods outperform many existing multi-step off-policy algorithms.
@article{wang2024highway, title = {Highway reinforcement learning}, author = {Wang, Yuhui and Strupl, Miroslav and Faccio, Francesco and Wu, Qingyuan and Liu, Haozhe and Grudzie{\'n}, Micha{\l} and Tan, Xiaoyang and Schmidhuber, J{\"u}rgen}, journal = {arXiv preprint arXiv:2405.18289}, year = {2024}, }







2023
- AAAI Oral
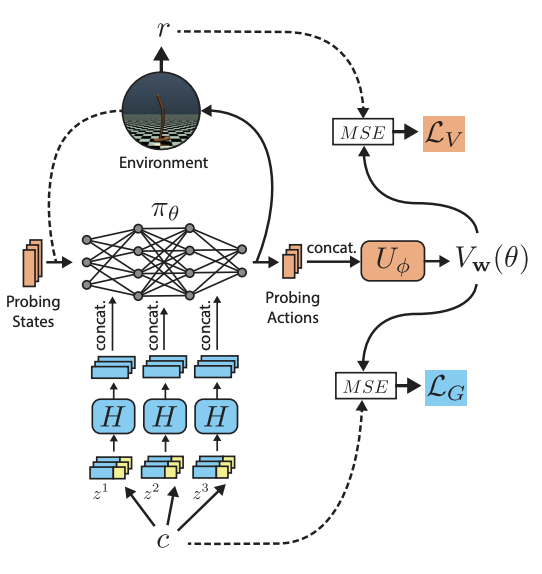 Goal-conditioned generators of deep policiesFrancesco Faccio, Vincent Herrmann, Aditya Ramesh, Louis Kirsch, and Jürgen SchmidhuberIn Proceedings of the AAAI Conference on Artificial Intelligence, 2023
Goal-conditioned generators of deep policiesFrancesco Faccio, Vincent Herrmann, Aditya Ramesh, Louis Kirsch, and Jürgen SchmidhuberIn Proceedings of the AAAI Conference on Artificial Intelligence, 2023Goal-conditioned Reinforcement Learning (RL) aims at learning optimal policies, given goals encoded in special command inputs. Here we study goal-conditioned neural nets (NNs) that learn to generate deep NN policies in form of context-specific weight matrices, similar to Fast Weight Programmers and other methods from the 1990s. Using context commands of the form "generate a policy that achieves a desired expected return," our NN generators combine powerful exploration of parameter space with generalization across commands to iteratively find better and better policies. A form of weight-sharing HyperNetworks and policy embeddings scales our method to generate deep NNs. Experiments show how a single learned policy generator can produce policies that achieve any return seen during training. Finally, we evaluate our algorithm on a set of continuous control tasks where it exhibits competitive performance. Our code is public.
@inproceedings{faccio2023goal, title = {Goal-conditioned generators of deep policies}, author = {Faccio, Francesco and Herrmann, Vincent and Ramesh, Aditya and Kirsch, Louis and Schmidhuber, J{\"u}rgen}, booktitle = {Proceedings of the AAAI Conference on Artificial Intelligence}, volume = {37}, number = {6}, pages = {7503--7511}, year = {2023}, } - NeurIPSW Best Paper
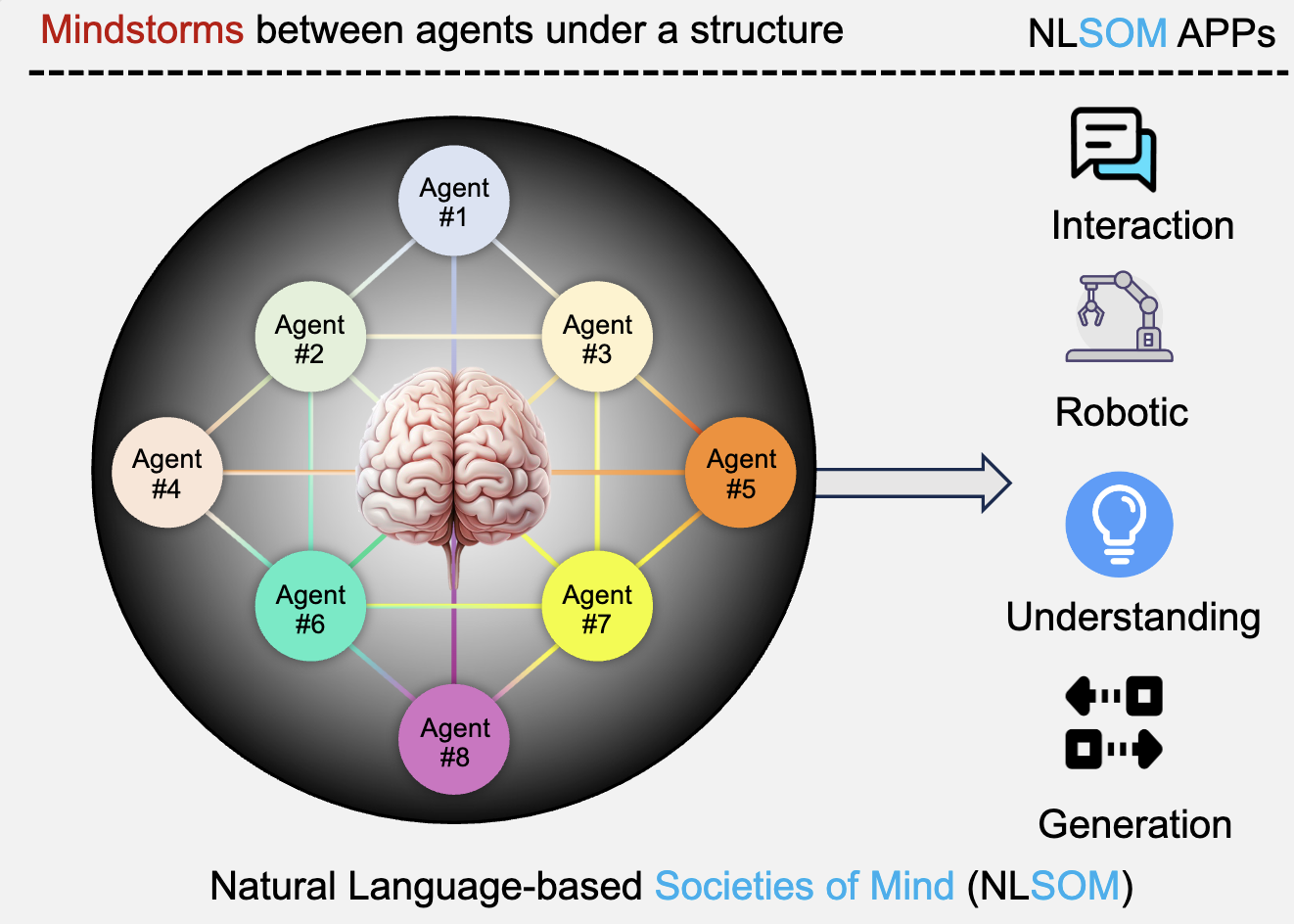 Mindstorms in natural language-based societies of mindMingchen Zhuge*, Haozhe Liu*, Francesco Faccio*, Dylan R Ashley*, Róbert Csordás, and 6 more authorsarXiv preprint arXiv:2305.17066, 2023
Mindstorms in natural language-based societies of mindMingchen Zhuge*, Haozhe Liu*, Francesco Faccio*, Dylan R Ashley*, Róbert Csordás, and 6 more authorsarXiv preprint arXiv:2305.17066, 2023Both Minsky’s "society of mind" and Schmidhuber’s "learning to think" inspire diverse societies of large multimodal neural networks (NNs) that solve problems by interviewing each other in a "mindstorm." Recent implementations of NN-based societies of minds consist of large language models (LLMs) and other NN-based experts communicating through a natural language interface. In doing so, they overcome the limitations of single LLMs, improving multimodal zero-shot reasoning. In these natural language-based societies of mind (NLSOMs), new agents – all communicating through the same universal symbolic language – are easily added in a modular fashion. To demonstrate the power of NLSOMs, we assemble and experiment with several of them (having up to 129 members), leveraging mindstorms in them to solve some practical AI tasks: visual question answering, image captioning, text-to-image synthesis, 3D generation, egocentric retrieval, embodied AI, and general language-based task solving. We view this as a starting point towards much larger NLSOMs with billions of agents-some of which may be humans. And with this emergence of great societies of heterogeneous minds, many new research questions have suddenly become paramount to the future of artificial intelligence. What should be the social structure of an NLSOM? What would be the (dis)advantages of having a monarchical rather than a democratic structure? How can principles of NN economies be used to maximize the total reward of a reinforcement learning NLSOM? In this work, we identify, discuss, and try to answer some of these questions.
@article{zhuge2023mindstorms, title = {Mindstorms in natural language-based societies of mind}, author = {Zhuge, Mingchen and Liu, Haozhe and Faccio, Francesco and Ashley, Dylan R and Csord{\'a}s, R{\'o}bert and Gopalakrishnan, Anand and Hamdi, Abdullah and Hammoud, Hasan Abed Al Kader and Herrmann, Vincent and Irie, Kazuki and others}, journal = {arXiv preprint arXiv:2305.17066}, year = {2023}, } - ICCV
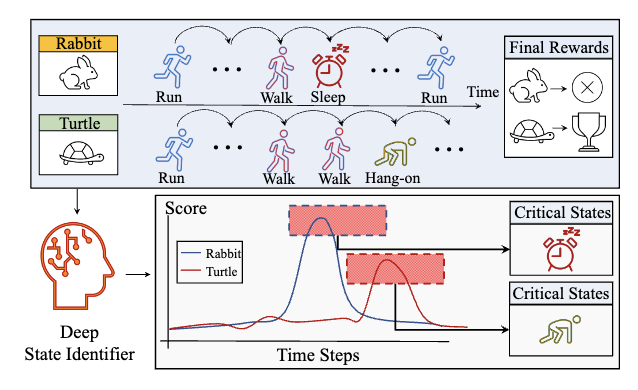 Learning to identify critical states for reinforcement learning from videosHaozhe Liu, Mingchen Zhuge, Bing Li, Yuhui Wang, Francesco Faccio, and 2 more authorsIn Proceedings of the IEEE/CVF International Conference on Computer Vision, 2023
Learning to identify critical states for reinforcement learning from videosHaozhe Liu, Mingchen Zhuge, Bing Li, Yuhui Wang, Francesco Faccio, and 2 more authorsIn Proceedings of the IEEE/CVF International Conference on Computer Vision, 2023Recent work on deep reinforcement learning (DRL) has pointed out that algorithmic information about good policies can be extracted from offline data which lack explicit information about executed actions. For example, videos of humans or robots may convey a lot of implicit information about rewarding action sequences, but a DRL machine that wants to profit from watching such videos must first learn by itself to identify and recognize relevant states/actions/rewards. Without relying on ground-truth annotations, our new method called Deep State Identifier learns to predict returns from episodes encoded as videos. Then it uses a kind of mask-based sensitivity analysis to extract/identify important critical states. Extensive experiments showcase our method’s potential for understanding and improving agent behavior.
@inproceedings{liu2023learning, title = {Learning to identify critical states for reinforcement learning from videos}, author = {Liu, Haozhe and Zhuge, Mingchen and Li, Bing and Wang, Yuhui and Faccio, Francesco and Ghanem, Bernard and Schmidhuber, J{\"u}rgen}, booktitle = {Proceedings of the IEEE/CVF International Conference on Computer Vision}, pages = {1955--1965}, year = {2023}, } - Preprint
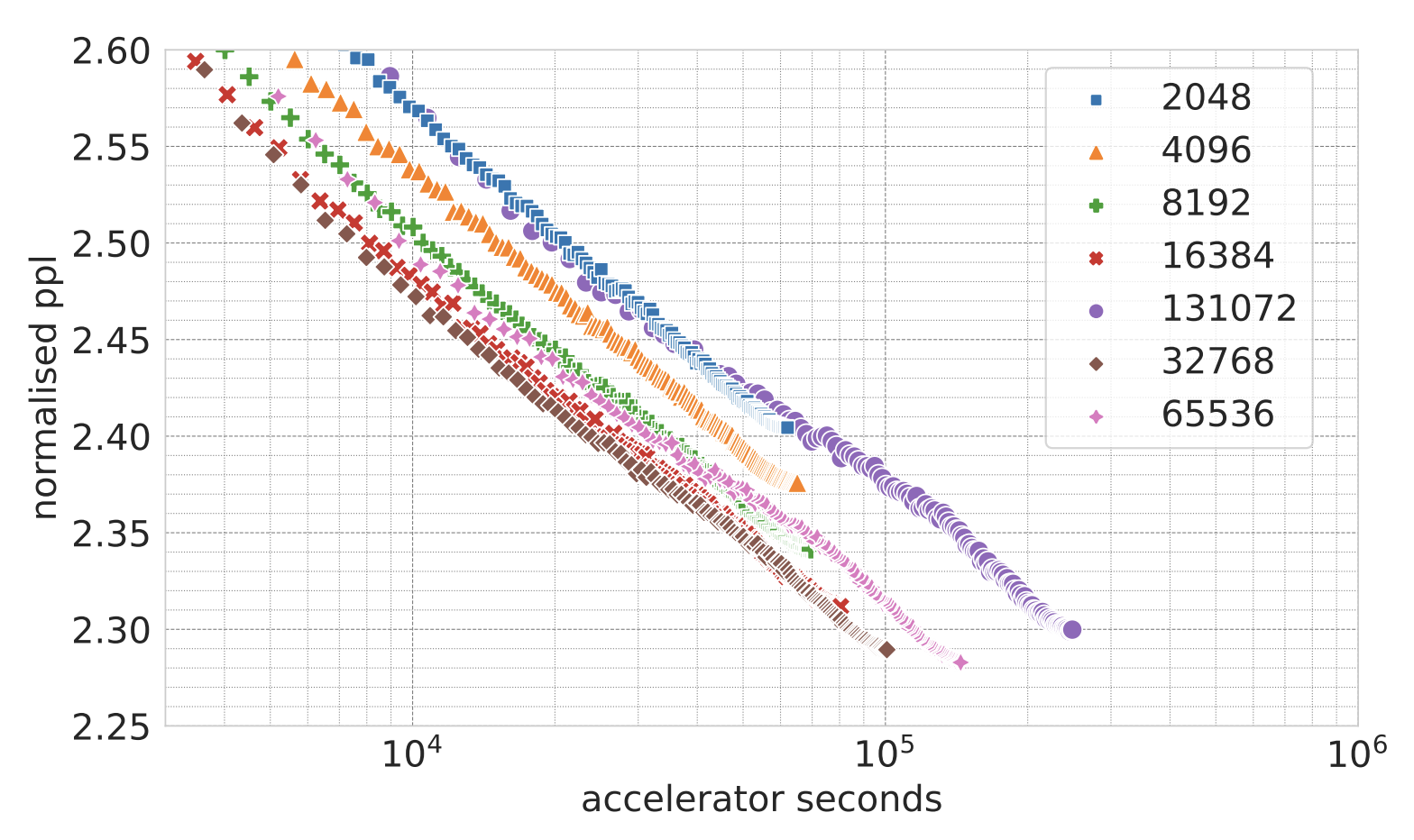 The Languini Kitchen: Enabling Language Modelling Research at Different Scales of ComputeAleksandar Stanić, Dylan Ashley, Oleg Serikov, Louis Kirsch, Francesco Faccio, and 3 more authorsarXiv preprint arXiv:2309.11197, 2023
The Languini Kitchen: Enabling Language Modelling Research at Different Scales of ComputeAleksandar Stanić, Dylan Ashley, Oleg Serikov, Louis Kirsch, Francesco Faccio, and 3 more authorsarXiv preprint arXiv:2309.11197, 2023The Languini Kitchen serves as both a research collective and codebase designed to empower researchers with limited computational resources to contribute meaningfully to the field of language modelling. We introduce an experimental protocol that enables model comparisons based on equivalent compute, measured in accelerator hours. The number of tokens on which a model is trained is defined by the model’s throughput and the chosen compute class. Notably, this approach avoids constraints on critical hyperparameters which affect total parameters or floating-point operations. For evaluation, we pre-process an existing large, diverse, and high-quality dataset of books that surpasses existing academic benchmarks in quality, diversity, and document length. On it, we compare methods based on their empirical scaling trends which are estimated through experiments at various levels of compute. This work also provides two baseline models: a feed-forward model derived from the GPT-2 architecture and a recurrent model in the form of a novel LSTM with ten-fold throughput. While the GPT baseline achieves better perplexity throughout all our levels of compute, our LSTM baseline exhibits a predictable and more favourable scaling law. This is due to the improved throughput and the need for fewer training tokens to achieve the same decrease in test perplexity. Extrapolating the scaling laws leads of both models results in an intersection at roughly 50,000 accelerator hours. We hope this work can serve as the foundation for meaningful and reproducible language modelling research.
@article{stanic2023languini, title = {The Languini Kitchen: Enabling Language Modelling Research at Different Scales of Compute}, author = {Stani{\'c}, Aleksandar and Ashley, Dylan and Serikov, Oleg and Kirsch, Louis and Faccio, Francesco and Schmidhuber, J{\"u}rgen and Hofmann, Thomas and Schlag, Imanol}, journal = {arXiv preprint arXiv:2309.11197}, year = {2023}, }




2022
- NeurIPS
 Neural differential equations for learning to program neural nets through continuous learning rulesKazuki Irie, Francesco Faccio, and Jürgen SchmidhuberAdvances in Neural Information Processing Systems, 2022
Neural differential equations for learning to program neural nets through continuous learning rulesKazuki Irie, Francesco Faccio, and Jürgen SchmidhuberAdvances in Neural Information Processing Systems, 2022Neural ordinary differential equations (ODEs) have attracted much attention as continuous-time counterparts of deep residual neural networks (NNs), and numerous extensions for recurrent NNs have been proposed. Since the 1980s, ODEs have also been used to derive theoretical results for NN learning rules, eg, the famous connection between Oja’s rule and principal component analysis. Such rules are typically expressed as additive iterative update processes which have straightforward ODE counterparts. Here we introduce a novel combination of learning rules and Neural ODEs to build continuous-time sequence processing nets that learn to manipulate short-term memory in rapidly changing synaptic connections of other nets. This yields continuous-time counterparts of Fast Weight Programmers and linear Transformers. Our novel models outperform the best existing Neural Controlled Differential Equation based models on various time series classification tasks, while also addressing their fundamental scalability limitations. Our code is public.
@article{irie2022neural, title = {Neural differential equations for learning to program neural nets through continuous learning rules}, author = {Irie, Kazuki and Faccio, Francesco and Schmidhuber, J{\"u}rgen}, journal = {Advances in Neural Information Processing Systems}, volume = {35}, pages = {38614--38628}, year = {2022}, } - AAAI
 Reward-weighted regression converges to a global optimumMiroslav Štrupl*, Francesco Faccio*, Dylan R Ashley, Rupesh Kumar Srivastava, and Jürgen SchmidhuberIn Proceedings of the AAAI Conference on Artificial Intelligence, 2022
Reward-weighted regression converges to a global optimumMiroslav Štrupl*, Francesco Faccio*, Dylan R Ashley, Rupesh Kumar Srivastava, and Jürgen SchmidhuberIn Proceedings of the AAAI Conference on Artificial Intelligence, 2022Reward-Weighted Regression (RWR) belongs to a family of widely known iterative Reinforcement Learning algorithms based on the Expectation-Maximization framework. In this family, learning at each iteration consists of sampling a batch of trajectories using the current policy and fitting a new policy to maximize a return-weighted log-likelihood of actions. Although RWR is known to yield monotonic improvement of the policy under certain circumstances, whether and under which conditions RWR converges to the optimal policy have remained open questions. In this paper, we provide for the first time a proof that RWR converges to a global optimum when no function approximation is used, in a general compact setting. Furthermore, for the simpler case with finite state and action spaces we prove R-linear convergence of the state-value function to the optimum.
@inproceedings{vstrupl2022reward, title = {Reward-weighted regression converges to a global optimum}, author = {{\v{S}}trupl, Miroslav and Faccio, Francesco and Ashley, Dylan R and Srivastava, Rupesh Kumar and Schmidhuber, J{\"u}rgen}, booktitle = {Proceedings of the AAAI Conference on Artificial Intelligence}, volume = {36}, number = {8}, pages = {8361--8369}, year = {2022}, } - Neural Computation
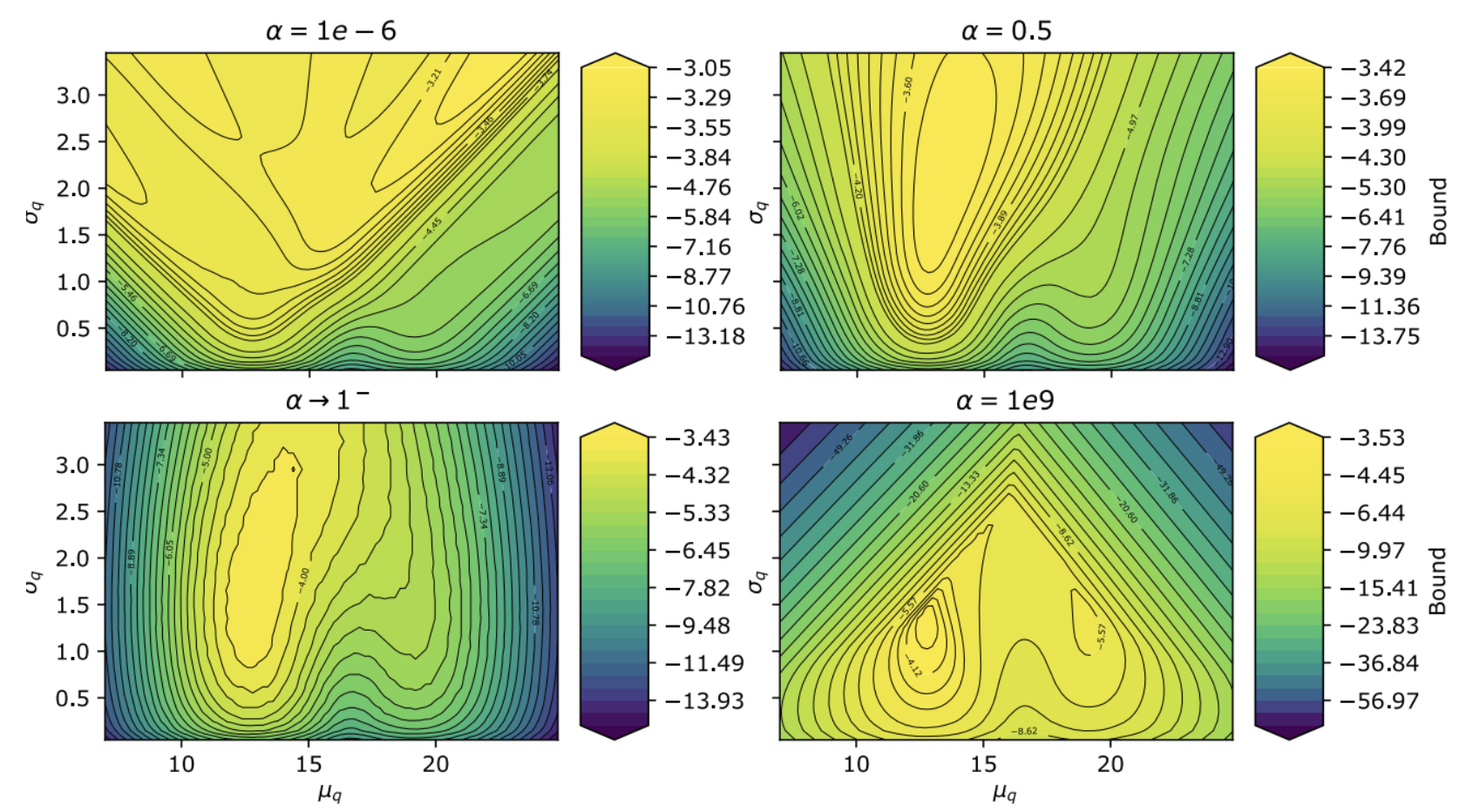 Bayesian brains and the Rényi divergenceNoor Sajid*, Francesco Faccio*, Lancelot Da Costa, Thomas Parr, Jürgen Schmidhuber, and 1 more authorNeural Computation, 2022
Bayesian brains and the Rényi divergenceNoor Sajid*, Francesco Faccio*, Lancelot Da Costa, Thomas Parr, Jürgen Schmidhuber, and 1 more authorNeural Computation, 2022Under the Bayesian brain hypothesis, behavioural variations can be attributed to different priors over generative model parameters. This provides a formal explanation for why individuals exhibit inconsistent behavioural preferences when confronted with similar choices. For example, greedy preferences are a consequence of confident (or precise) beliefs over certain outcomes. Here, we offer an alternative account of behavioural variability using Rényi divergences and their associated variational bounds. Rényi bounds are analogous to the variational free energy (or evidence lower bound) and can be derived under the same assumptions. Importantly, these bounds provide a formal way to establish behavioural differences through an α parameter, given fixed priors. This rests on changes in α that alter the bound (on a continuous scale), inducing different posterior estimates and consequent variations in behaviour. Thus, it looks as if individuals have different priors, and have reached different conclusions. More specifically, α→0+ optimisation leads to mass-covering variational estimates and increased variability in choice behaviour. Furthermore, α→+∞ optimisation leads to mass-seeking variational posteriors and greedy preferences. We exemplify this formulation through simulations of the multi-armed bandit task. We note that these α parameterisations may be especially relevant, i.e., shape preferences, when the true posterior is not in the same family of distributions as the assumed (simpler) approximate density, which may be the case in many real-world scenarios. The ensuing departure from vanilla variational inference provides a potentially useful explanation for differences in behavioural preferences of biological (or artificial) agents under the assumption that the brain performs variational Bayesian inference.
@article{sajid2022bayesian, title = {Bayesian brains and the R{\'e}nyi divergence}, author = {Sajid, Noor and Faccio, Francesco and Da Costa, Lancelot and Parr, Thomas and Schmidhuber, J{\"u}rgen and Friston, Karl}, journal = {Neural Computation}, volume = {34}, number = {4}, pages = {829--855}, year = {2022}, publisher = {MIT Press One Rogers Street, Cambridge, MA 02142-1209, USA journals-info~…}, } - Preprint
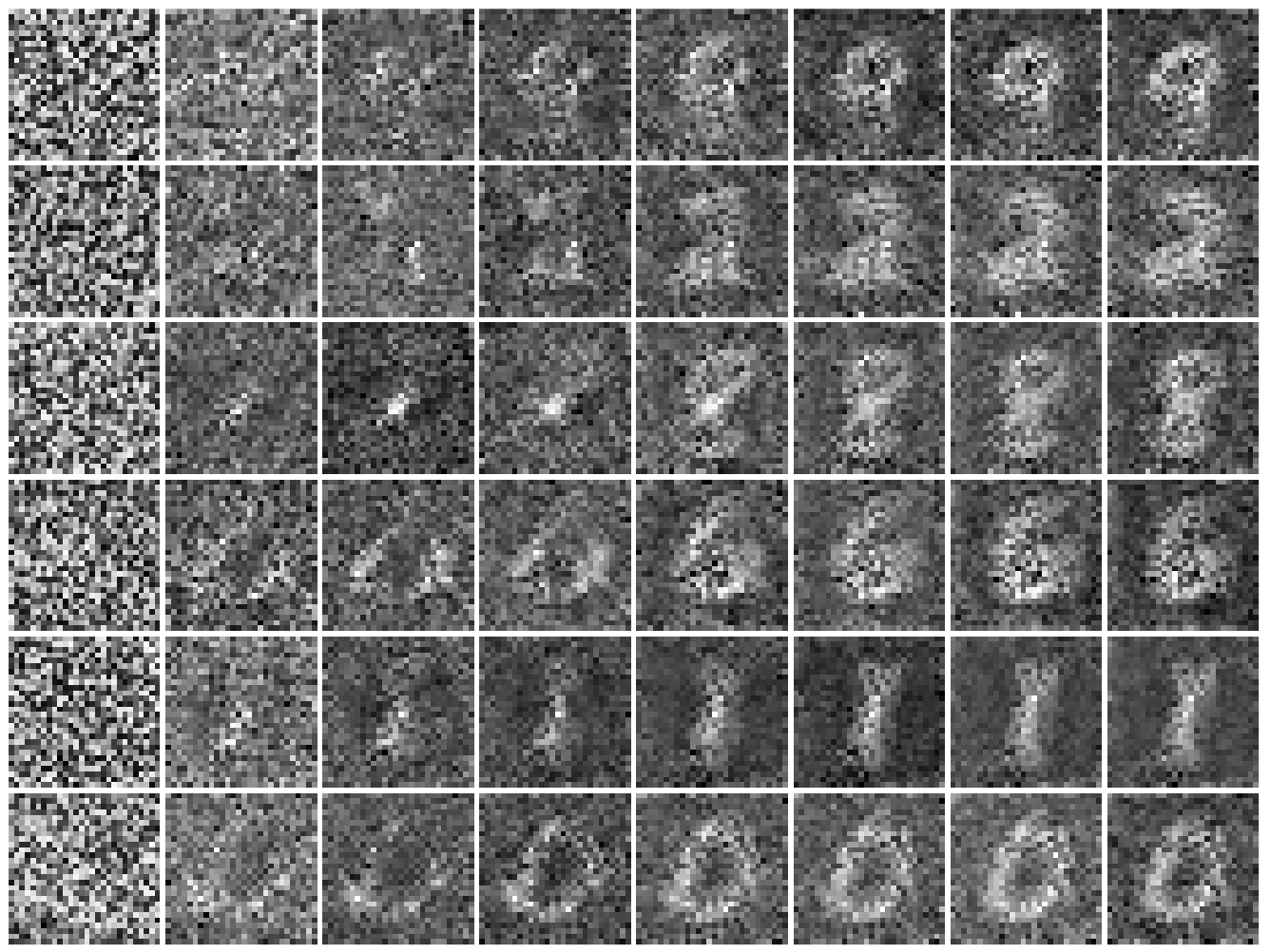 General policy evaluation and improvement by learning to identify few but crucial statesFrancesco Faccio, Aditya Ramesh, Vincent Herrmann, Jean Harb, and Jürgen SchmidhuberarXiv preprint arXiv:2207.01566, 2022
General policy evaluation and improvement by learning to identify few but crucial statesFrancesco Faccio, Aditya Ramesh, Vincent Herrmann, Jean Harb, and Jürgen SchmidhuberarXiv preprint arXiv:2207.01566, 2022Learning to evaluate and improve policies is a core problem of Reinforcement Learning (RL). Traditional RL algorithms learn a value function defined for a single policy. A recently explored competitive alternative is to learn a single value function for many policies. Here we combine the actor-critic architecture of Parameter-Based Value Functions and the policy embedding of Policy Evaluation Networks to learn a single value function for evaluating (and thus helping to improve) any policy represented by a deep neural network (NN). The method yields competitive experimental results. In continuous control problems with infinitely many states, our value function minimizes its prediction error by simultaneously learning a small set of ‘probing states’ and a mapping from actions produced in probing states to the policy’s return. The method extracts crucial abstract knowledge about the environment in form of very few states sufficient to fully specify the behavior of many policies. A policy improves solely by changing actions in probing states, following the gradient of the value function’s predictions. Surprisingly, it is possible to clone the behavior of a near-optimal policy in Swimmer-v3 and Hopper-v3 environments only by knowing how to act in 3 and 5 such learned states, respectively. Remarkably, our value function trained to evaluate NN policies is also invariant to changes of the policy architecture: we show that it allows for zero-shot learning of linear policies competitive with the best policy seen during training. Our code is public.
@article{faccio2022general, title = {General policy evaluation and improvement by learning to identify few but crucial states}, author = {Faccio, Francesco and Ramesh, Aditya and Herrmann, Vincent and Harb, Jean and Schmidhuber, J{\"u}rgen}, journal = {arXiv preprint arXiv:2207.01566}, year = {2022}, } - Preprint
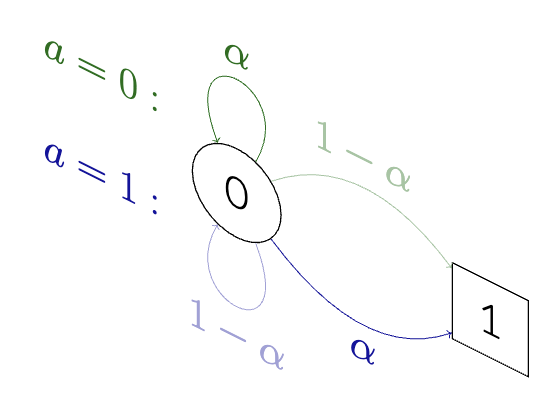 Upside-down reinforcement learning can diverge in stochastic environments with episodic resetsMiroslav Štrupl, Francesco Faccio, Dylan R Ashley, Jürgen Schmidhuber, and Rupesh Kumar SrivastavaarXiv preprint arXiv:2205.06595, 2022
Upside-down reinforcement learning can diverge in stochastic environments with episodic resetsMiroslav Štrupl, Francesco Faccio, Dylan R Ashley, Jürgen Schmidhuber, and Rupesh Kumar SrivastavaarXiv preprint arXiv:2205.06595, 2022Upside-Down Reinforcement Learning (UDRL) is an approach for solving RL problems that does not require value functions and uses only supervised learning, where the targets for given inputs in a dataset do not change over time. Ghosh et al. proved that Goal-Conditional Supervised Learning (GCSL) – which can be viewed as a simplified version of UDRL – optimizes a lower bound on goal-reaching performance. This raises expectations that such algorithms may enjoy guaranteed convergence to the optimal policy in arbitrary environments, similar to certain well-known traditional RL algorithms. Here we show that for a specific episodic UDRL algorithm (eUDRL, including GCSL), this is not the case, and give the causes of this limitation. To do so, we first introduce a helpful rewrite of eUDRL as a recursive policy update. This formulation helps to disprove its convergence to the optimal policy for a wide class of stochastic environments. Finally, we provide a concrete example of a very simple environment where eUDRL diverges. Since the primary aim of this paper is to present a negative result, and the best counterexamples are the simplest ones, we restrict all discussions to finite (discrete) environments, ignoring issues of function approximation and limited sample size.
@article{vstrupl2022upside, title = {Upside-down reinforcement learning can diverge in stochastic environments with episodic resets}, author = {{\v{S}}trupl, Miroslav and Faccio, Francesco and Ashley, Dylan R and Schmidhuber, J{\"u}rgen and Srivastava, Rupesh Kumar}, journal = {arXiv preprint arXiv:2205.06595}, year = {2022}, }





2021
- ICLR
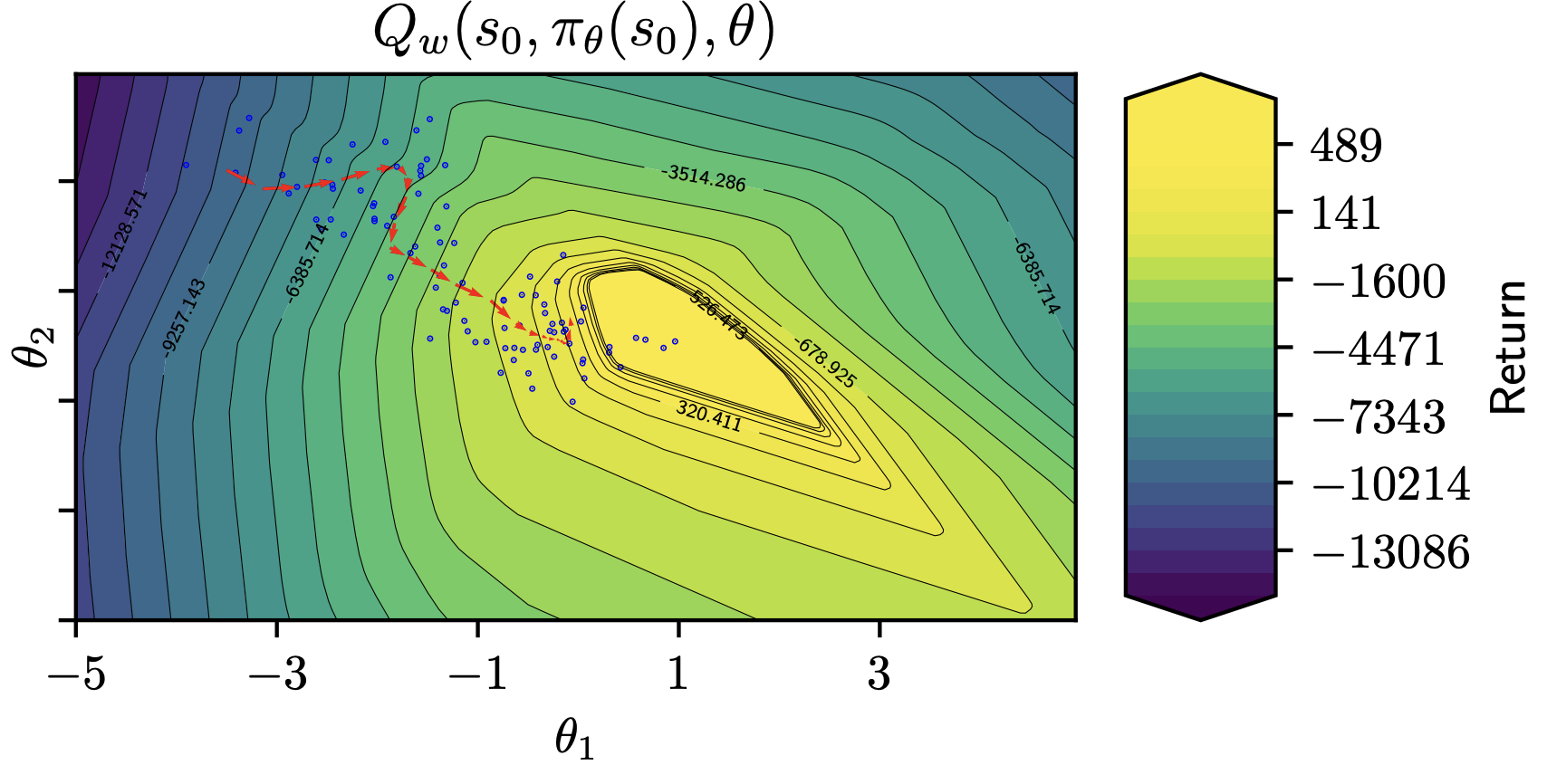 Parameter-Based Value FunctionsFrancesco Faccio, Louis Kirsch, and Jürgen SchmidhuberIn International Conference on Learning Representations, 2021
Parameter-Based Value FunctionsFrancesco Faccio, Louis Kirsch, and Jürgen SchmidhuberIn International Conference on Learning Representations, 2021Traditional off-policy actor-critic Reinforcement Learning (RL) algorithms learn value functions of a single target policy. However, when value functions are updated to track the learned policy, they forget potentially useful information about old policies. We introduce a class of value functions called Parameter-Based Value Functions (PBVFs) whose inputs include the policy parameters. They can generalize across different policies. PBVFs can evaluate the performance of any policy given a state, a state-action pair, or a distribution over the RL agent’s initial states. First we show how PBVFs yield novel off-policy policy gradient theorems. Then we derive off-policy actor-critic algorithms based on PBVFs trained by Monte Carlo or Temporal Difference methods. We show how learned PBVFs can zero-shot learn new policies that outperform any policy seen during training. Finally our algorithms are evaluated on a selection of discrete and continuous control tasks using shallow policies and deep neural networks. Their performance is comparable to state-of-the-art methods.
@inproceedings{faccioparameter, title = {Parameter-Based Value Functions}, author = {Faccio, Francesco and Kirsch, Louis and Schmidhuber, J{\"u}rgen}, booktitle = {International Conference on Learning Representations}, year = {2021}, }

2018
- NeurIPS Oral
 Policy optimization via importance samplingAlberto Maria Metelli, Matteo Papini, Francesco Faccio, and Marcello RestelliAdvances in Neural Information Processing Systems, 2018
Policy optimization via importance samplingAlberto Maria Metelli, Matteo Papini, Francesco Faccio, and Marcello RestelliAdvances in Neural Information Processing Systems, 2018Policy optimization is an effective reinforcement learning approach to solve continuous control tasks. Recent achievements have shown that alternating online and offline optimization is a successful choice for efficient trajectory reuse. However, deciding when to stop optimizing and collect new trajectories is non-trivial, as it requires to account for the variance of the objective function estimate. In this paper, we propose a novel, model-free, policy search algorithm, POIS, applicable in both action-based and parameter-based settings. We first derive a high-confidence bound for importance sampling estimation; then we define a surrogate objective function, which is optimized offline whenever a new batch of trajectories is collected. Finally, the algorithm is tested on a selection of continuous control tasks, with both linear and deep policies, and compared with state-of-the-art policy optimization methods.
@article{metelli2018policy, title = {Policy optimization via importance sampling}, author = {Metelli, Alberto Maria and Papini, Matteo and Faccio, Francesco and Restelli, Marcello}, journal = {Advances in Neural Information Processing Systems}, volume = {31}, year = {2018}, }

